
Aufbau von Datenbanken
Datenbanken als eine Form des Informations- und Wissensmanagements
Der Begriff Datenbank ist für viele Nutzer ein Mysterium. Dabei sind die meisten Menschen, wenn sie denn z.B. „online gehen“ mit Datenbanken in Kontakt: etwa wenn sie sich mit Ihrem Kundenkonto bei einem Onlinehändler anmelden oder auch nur die Angebote auf dessen Website studieren. Immer steckt dahinter eine Datenbank.
Im vorliegenden Kapitel geht es darum, dass wir uns mit dem Begriff und dem, was sich dahinter verbirgt, vertraut machen. So sind die Inhalte dieses Kapitels:
- Wo werden Datenbanken eingesetzt?
- Welche Organisations- bzw. Speicherform der Datenspeicherung ist die beste vor dem Hintergrund sehr großer Datenmengen?
- Was versteht man unter einer relationalen Datenbank?
- Worin besteht der Vorteil/bestehen die Vorteile von relationalen Datenbanken gegenüber der Datenspeicherung in klassischen Dateien i.F.v. Tabellen?
- Aus welchen Elementen besteht die Datenbasis?
- Welche Aufgaben hat ein Datenbanksystem?
Wo werden Datenbanken eingesetzt?
Um den Sinn von Datenbanken und deren Rolle in der Informations- und Wissensspeicherung im digitalen Zeitalter anschaulich zu vermitteln, soll hier ein Beispiel aus der „analogen Zeit“ bemüht werden: Um für ein Referat oder eine wissenschaftliche Arbeit die notwendigen belastbaren Quellen zu finden, nutzten die Autoren diverse Wissensquellen bzw. Nachschlagewerke, wie z.B. den Brockhaus oder Meyers Konversationslexikon.

Analoge Recherche in einer Bibliothek; Quelle: Pixabay
Die beiden letztgenannten Werke waren bzw. sind alphabetisch aufgebaut. An einer Fundstelle sind nicht selten mehrere Querverweise zu finden – umgangssprachlich würde man heute von „Links“ sprechen – sodass binnen kurzem mehrere der nicht gerade handlichen Bände des jeweiligen Lexikons geöffnet auf dem Schreibtisch und/oder dem Boden des Arbeitszimmers verteilt lagen. Entsprechend schwierig war es, den Überblick zu behalten. Wie angenehm wäre es da gewesen, wenn die verschiedenen Fundstellen und Querverweise in einem kompakten und damit übersichtlichen Verzeichnis hätten abgelegt werden können, um später darauf zurück zu greifen.
Seitdem die elektronische Datenverarbeitung in nahezu allen Lebensbereichen unserer modernen Gesellschaft Einzug gehalten hat, sind Datenbanken für Speicherung und Zugriff von bzw. auf Wissen nicht mehr aus dem beruflichen aber auch dem privaten Leben wegzudenken. So gehört es in Bibliotheken zum Standard, dass der Medienbestand an PC-Arbeitsplätzen anhand von Datenbanken durchsucht werden kann. Digitale Medienangebote im Netz, wie z.B. die Onlineausgaben von Tageszeitungen, basieren ebenso auf Datenbanken. Zu guter Letzt sind Datenbanken auch ein essentieller Bestandteil von Online. bzw. Versandhändlern.
Halten wir fest: Datenbanken werden überall dort eingesetzt, wo es gilt, große Datenmengen strukturiert zu speichern und für den späteren Zugriff bereit zu halten.
Welche Organisations- bzw. Speicherform der Datenspeicherung ist die beste, wenn es sich um sehr große Datenmengen handelt?
Um nun Schritt für Schritt den Aufbau einer (relationalen) Datenbank sowie dessen bzw. deren Sinnhaftigkeit zu verstehen, wollen wir uns verschiedene Möglichkeiten der Datenspeicherung in Dateien näher betrachten. Als erstes Beispiel soll ein Ausschnitt aus der Sammlung weniger persönlicher Daten(-sätze) einiger Personen einer Schule dienen:

Speicherung von Daten in Form eines Fließtextes
Die Daten wurden als Fließtext in einem Textverarbeitungsprogramm gespeichert: Neben der relativen Unübersichtlichkeit der einzelnen Persönlichkeitsmerkmale (z.B. Name, PLZ, Personalnummer) ist das Ordnen bzw. Finden von einzelnen Personen anhand bestimmter Merkmale relativ aufwändig, da diese Aufgaben nicht zu den Stärken von Textverarbeitungsprogrammen gehören. Zugleich können die Daten in den meisten Fällen nur mit einem Textverarbeitungsprogramm geöffnet und gelesen werden.
Einige dieser Nachteile können beseitigt werden, indem die Daten in Form einer Tabelle gespeichert werden, was z.B. mit MS Excel erfolgen könnte. Das Ergebnis könnte wie folgt aussehen:

Speicherung von Daten in Form einer Tabelle
Der Vorteil der Speicherung in Tabellenform besteht zunächst im Zugewinn von Übersichtlichkeit. Zudem können die Daten z.B. als CSV-Daten in anderen Programmen (z.B. einfache Texteditoren) weiterverarbeitet werden. Dadurch wird die Weiterverwendung z.T. erheblich vereinfacht.
Als nachteilig stellt sich jedoch bei näherem Hinsehen heraus, dass ein und dieselbe Information z.T. mehrmals und dabei unterschiedlich gespeichert wurde:

Widersprüche in der tabellarischen Datenspeicherung
Im Beispiel wird der Ort „Nürnberg“ in den ersten beiden Zeilen auf unterschiedliche Weisen geschrieben. In der letzten Zeile kommt noch ein offensichtlicher Tippfehler dazu. Worin die Gründe für die unterschiedlichen Schreibweisen auch liegen mögen – hierdurch entstehen in jedem Fall Widersprüche – die Daten sind inkonsistent.
Wollte man jetzt z.B. alle Personen mit Wohnsitz in Nürnberg aus der Tabelle mittels Filter o.ä. extrahieren, so wäre das Ergebnis aufgrund der unterschiedlichen Schreibweise in jedem Fall unvollständig.
Auf die unterschiedliche Darstellungsform des jeweiligen Geschlechts gehen wir später ein.
 |
Halten wir fest: |
- Die Speicherung von Daten in tabellarischer Form hat gegenüber der Speicherung als Fließtext zunächst einmal den Vorteil der Übersichtlichkeit, verbunden mit der Möglichkeit, den Tabelleninhalt nach bestimmten Kriterien durchsuchen zu lassen, und die Daten mit verschiedenen Programmen weiterverarbeiten zu können.
- Die Mehrfachspeicherung ein und derselben Information – hier des Ortes – bezeichnet man als Redundanz. Durch sie entsteht die Problematik der o.g Widersprüche, durch welche die Daten inkonsistent werden.
- Ein Widerspruch kann nur entstehen, wenn eine Information mehrfach vorhanden – redundant – ist. Das hat ggf. zur Folge, dass der Datenbestand inkosistent wird.
Als Ergebnis der Feststellungen gilt es zu überlegen, wie die Redundanzen und die sich daraus ergebenden Inkonsistenzen vermieden werden können.
Aufgabe
Um die Problematik von mehrfach vorkommenden Daten zu erfahren, laden Sie sich das Word-Dokument hier herunter. Importieren Sie die Daten in ein Tabellenkalkulationsprogramm. Versuchen Sie, die einzelnen Merkmale in separate Spalten zu überführen. Wenn Sie fertig sind, gehen Sie folgende Schritte durch:
- Kopieren Sie die Spalten mit den Merkmalen, welche mehrfach vorkommen, in ein jeweils neues Tabellenblatt.
- Entfernen Sie mit Hilfe des Programms alle Duplikate aus den jeweiligen Tabellenblättern (MS Excel: Daten|Duplikate entfernen).
- Löschen Sie alle Spalten mit den Merkmalen, die Sie in die neuen Tabellenblätter überführt haben, aus dem ersten Tabellenblatt.
- Überlegen Sie, wie es möglich ist, jedem Personendatensatz die ursprünglichen Informationen wieder anzufügen, ohne dass erneut Wiederholungen in der Datei entstehen.
Die Tabellenblätter mit den Attributen, welche Mehrfachnennungen enthielten, sehen folgendermaßen aus:
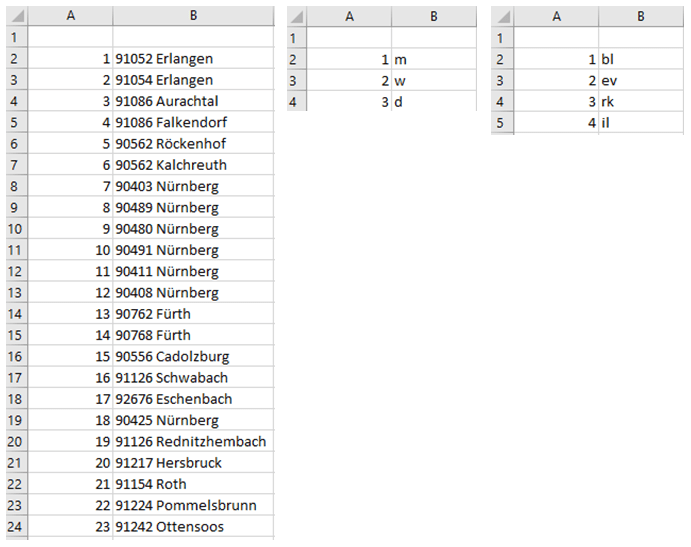
Um die Informationen nun wieder in die ursprüngliche Tabelle einzufügen, ist es, erforderlich, den einzelnen Datensätzen die jeweilige Kennzahl von PLZ und Ort, dem Geschlecht und dem Bekenntnis anzufügen:
Platzhalter
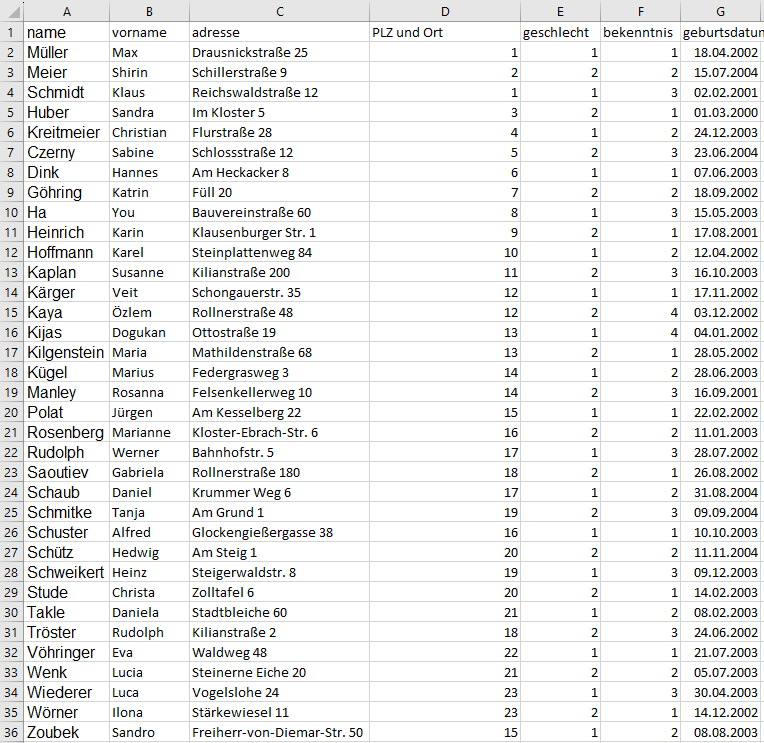
Damit wir den Aufbau einer relationalen Datenbank begreifen und dessen Sinn verstehen können, lassen wir die Probleme von Widersprüchen in der Spalte des Ortes zunächst einmal außer acht, sondern sehen uns das Merkmal „Geschlecht“ an (obige Abbildung): Jeder Person ist innerhalb der entsprechenden Spalte ein Geschlecht zugeordnet. Das geschieht in unserem Beispiel auf unterschiedliche Art und Weise, wie wir sehen können.
Wollte man aus dem Datenbestand nun alle Personen mit einer bestimmten Merkmalsausprägung abfragen, müssten bei der Formulierung der Bedingung(-en) möglichst alle infrage kommenden Speicherformen berücksichtigt werden – bei umfangreichen Datenbeständen ein relativ schwieriges Unterfangen. Es wäre daher wünschenswert, die Art und Weise der Speicherung dieser Eigenschaft von vorneherein festzulegen. Um dies zu gewährleisten, importieren wir die Inhalte des Tabellenblattes mit den Personendaten (in einem Verfahren, welches an späterer Stelle noch beschrieben wird) in MS Access:

Speicherung der Personendaten in einer Relation
Um für ein einheitliche Speicherung des Geschlechtsmerkmals in unserer Datenbank zu sorgen, eliminieren wir das Merkmal in einer gesonderten Relation:

Speicherung der möglichen Geschlechtsaufprägungen in einer Relation
Die konsequente Umsetzung in einer (kleinen) relationalen Datenbank sieht folgendermaßen aus:

Verknüpfung der Relationen „tbl_person“ und „tbl_geschlecht“
Sehen wir uns nun die Daten der Relation „tbl_person“ an:

Relation „tbl_person“ mit geschlechts_nr
| Halten wir fest: |
- Bei unseren Überlegungen stoßen wir auf eine mögliche Lösung, die aus mehreren Tabellen besteht.
- Die Informationen der einen Tabelle sind mit der/den anderen Tabelle/n verknüpft.
Grundsätzlich entspricht diese Datenanordnung und -verknüpfung dem Aufbau einer relationalen Datenbank:
- Diese bestehen aus mehreren Tabellen, welche miteinander verknüpft sind.
- Die Tabellen werden im Zusammenhang mit Datenbanken als Relationen bezeichnet.
- Durch die Erstellung mehrerer Relationen ist es möglich, Wiederholungen in den gespeicherten Daten (Redundanzen) zu vermeiden.
Ebenso ist es in diesem Zusammenhang in der relationalen Datenbank möglich, alle Ortsnamen in einer eigenen Relation zu speichern. In der Relation der Personendatensätze müsste dann nur noch auf den Datensatz des Ortes aus der Relation mit den Ortsnamen verwiesen werden, in welchem die jeweilige Person wohnt. Das hat zur Folge, dass alle Ortsnamen jeweils nur einmal gespeichert sind. Redundanzen und daraus entstehende mögliche Widersprüche, die zu Inkonsistenzen führen würden, sind damit auch an dieser Stelle beseitigt.
Aufgabe
Überlegen Sie, wie die Forderung nach einer Vermeidung der Mehrfachnennung von Ortsnamen in unserer kleinen Datenbank umgesetzt werden kann. Zeichnen Sie in Anlehnung der obigen Abbildungen die neue Relation und verbinden Sie sie mit der Relation „tbl_person“.
Die Lösung kann folgendermaßen aussehen:
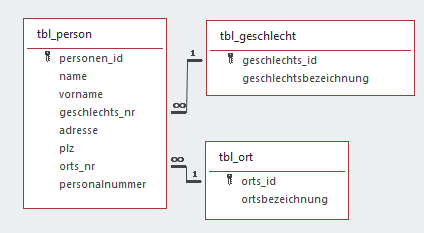
Eine neu erstellte Relation „tbl_ort“ wird mit der Relation „tbl_person“ über die Attribute orts_id (in „tbl_ort“) und orts_nr (in „tbl_person“) verbunden:
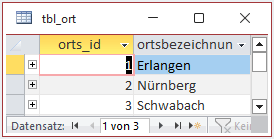
Der Inhalt der Relation „tbl_ort“ umfasst folgende Daten:
Das wirkt sich auf den Inhalt der Relation „tbl_person“ folgendermaßen aus:
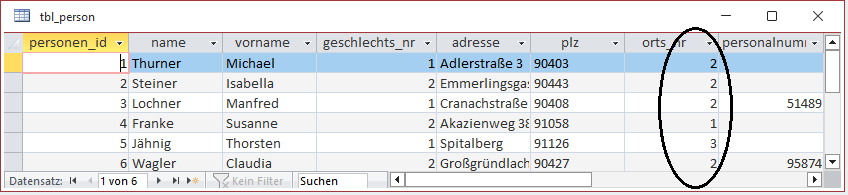
Platzhalter
Beim Aufbau einer Datenbank lassen sich alle Datensätze mit gleichen Merkmalen jeweils in eine Tabelle speichern, die im Zusammenhang mit Datenbanken „Relation“ genannt wird. Jeder Datensatz in einer dieser Tabellen wird mit einer Identifikationsnummer versehen, kurz ID genannt. Damit ist jeder Datensatz innerhalb einer Tabelle einmalig, was ihn zu einer Entität (einmaliger Datensatz) macht. Die ID übernimmt die Rolle eines Schüssels, mit dessen Hilfe jeder Ort in der Tabelle auffindbar ist.
In unserem Beispiel lassen sich nun alle Wohnorte in einer Tabelle speichern, wobei diese Tabelle zunächst nur die Spalten (Merkmale) „Orts_ID“ und „Ortsname“ hat. Jeder Ort wird darin ein einziges Mal abgespeichert, womit Widersprüche in der Schreibweise ausgeschlossen sind.
Genauso wie die Orte werden die Personaldatensätze ebenfalls in einer Tabelle gespeichert, wobei hier jeder Datensatz eine „Personal_ID bekommt. Anstelle der Ortsnamen werden nun in jedem Personendatensatz lediglich die Orts_ID abgespeichert.
Was versteht man unter einer relationalen Datenbank?
Wie wir gesehen haben, macht es Sinn, Daten gemäß ihrer Zusammengehörigkeit (gleiche Merkmale) in einzelnen Tabellen zusammenzufassen.
| In diesem Zusammenhang merken wir uns: |
- Eine relationale Datenbank besteht aus mehreren, miteinander verbundenen Tabellen, die im Zusammenhang mit Datenbanken Relationen genannt werden.
- Eine Zeile in einer Relation repräsentiert einen Datensatz.
- Jeder Datensatz besteht aus mehreren Spalten, die ihrerseits bestimmte Eigenschaften von ihm – Attribute, Merkmale – aufnehmen.
- In einer Relation werden Datensätze zusammengefasst, welche über die gleichen Attribute verfügen. So haben z.B. die Informationen über die Personen alle die Attribute „Name“, „Vorname“, „Adresse“, „PLZ“ (und zunächst „Ort“) gemeinsam. Selbstverständlich müssen die jeweiligen Ausprägungen, z.B. der Name, nicht identisch sein.
- Um zu gewährleisten, dass jeder Datensatz eindeutig ist und sich zu diesem Zweck in mindestens einem Attribut von den anderen in der Relation unterscheiden muss, bekommt er eine Identifikationsnummer, ID genannt. Sie dient als Primärschlüssel und wird stets mit dem Suffix (Zusatz) „_id“ benannt.
- Die Information, welche sich hinter einem Primärschlüssel verbirgt, kann als Fremschlüssel in eine andere Relation übertragen werden und wird dort einheitlich mit dem Suffix „_nr“ benannt. Beispiel: „geschlechts_id“ aus tbl_geschlecht“ wird als „geschlechts_nr“ in tbl_person weitergegeben.
- Durch die Vergabe von – innerhalb einer Relation – eindeutigen IDs wird jeder Datensatz einmalig und damit zu einer Entität.
- Die Relationen sind allesamt durch Beziehungen miteinander verbunden, damit keine Information – in unserem Beispiel die des Wohnortes und des Geschlechts – durch die Aufteilung der Daten auf mehrere Relationen verloren geht:
Die Relationen sowie die Beziehungen zwischen ihnen bilden in ihrer Gesamtheit die Datenbasis einer Datenbank.
Ein weiterer Vorteil der Speicherung von großen Datenmengen in Form einer Datenbank gegenüber der Speicherung in einer einzigen Tabelle eines Tabellenkalkulationsprogrammes ist der, dass auf die Datenbasis mit unterschiedlichen Programmen (MS Access, Oracle, SAP, etc.) zugegriffen werden kann. Diese Programme, mit welchen die Daten einer Datenbank verwaltet werden, nennt man Datenbankmanagementsysteme (DBMS). Durch diesen Umstand ist festzuhalten, dass eine Datenbank grundsätzlich aus der Datenbasis und dem jeweiligen DBMS besteht.
Folgende Abbildung veranschaulicht die Zusammenhänge:

Bestandteile des Datenbanksystems
Wie zu erkennen ist, blieben im Zuge der Umstrukturierung der Daten alle Informationen erhalten. Zugleich wurden fast alle möglichen Mehrfachnennungen beseitigt:
Überlegen Sie, wie das Attribut „PLZ“ so in die Datenbank integriert werden kann, dass auch hier keine Mehrfachnennungen mehr möglich/nötig sind.
Rufen wir uns die Ausgangssituation ins Gedächtnis, in welcher die Daten der sechs Personen in einer einfachen Excel-Tabelle gespeichert waren. Es stellt sich die Frage, ob der erhebliche Mehraufwand, welcher mit der Erstellung einer (zunächst kleinen) Datenbank einhergeht, gerechtfertigt ist – und wenn ja: welche weiteren Vorteile die Organisation der Daten in einer Datenbank mit sich bringt.
Worin besteht der Mehrwert von relationalen Datenbanken gegenüber der Datenspeicherung in klassischen Dateien i.F.v. Tabellen?
| Um den Mehraufwand zu rechtfertigen, den die Konzeption einer Datenbank gegenüber der Speicherung von Daten in einer „einfachen“ Tabelle mit sich bringt, wollen wie deren Vorteile zusammenfassen: |
- Stammdaten (Ortsnamen, Geschlecht, Bekenntnis, etc.) werden jeweils nur einmal in der Datenbank gespeichert.
- Dadurch gibt es in der Datenbank keine Redundanzen und das Datenaufkommen ist relativ gering.
- Durch das Vermeiden von Redundanzen sind Widersprüche ausgeschlossen.
- Damit ist die Konsistenz der Daten innerhalb der Datenbank gewährleistet.
- Die Formulierung von Abfragen gestaltet sich damit relativ einfach, da z.B. im Falle des Wohnortes nur nach einer Schreibweise gesucht werden muss.
- Auf die Daten kann mit unterschiedlichen Datenbankmanagementsystemen zugegriffen werden. Damit ist eine weitestgehende Programm- bzw. Anwendungsunabhängigkeit der Datenbasis gewährleistet.
- Mehrfachzugriff: Während auf eine herkömmliche Datei nur jeweils ein Benutzer mit Schreibrechten exklusiv zugreifen kann, ist es einem DBMS möglich, gleichzeitig mehreren Benutzern Schreib- u./o. Lesezugriff zu ermöglichen.
Alles in allem können wir an dieser Stelle festhalten, dass die Speicherung von umfangreichen Daten in einer Datenbank in ihrer Gesamtheit erhebliche Vorteile gegenüber der Speicherung in herkömmlichen Dateien hat.